
Cientistas publicam artigo onde explicam como criaram uma rede neural que supera as redes neurais de aprendizado profundo “tradicionais” em um desafio de reconhecimento de texto, sendo 300 vezes mais eficientes em termos de dados e demonstrando excelente capacidade de generalização.

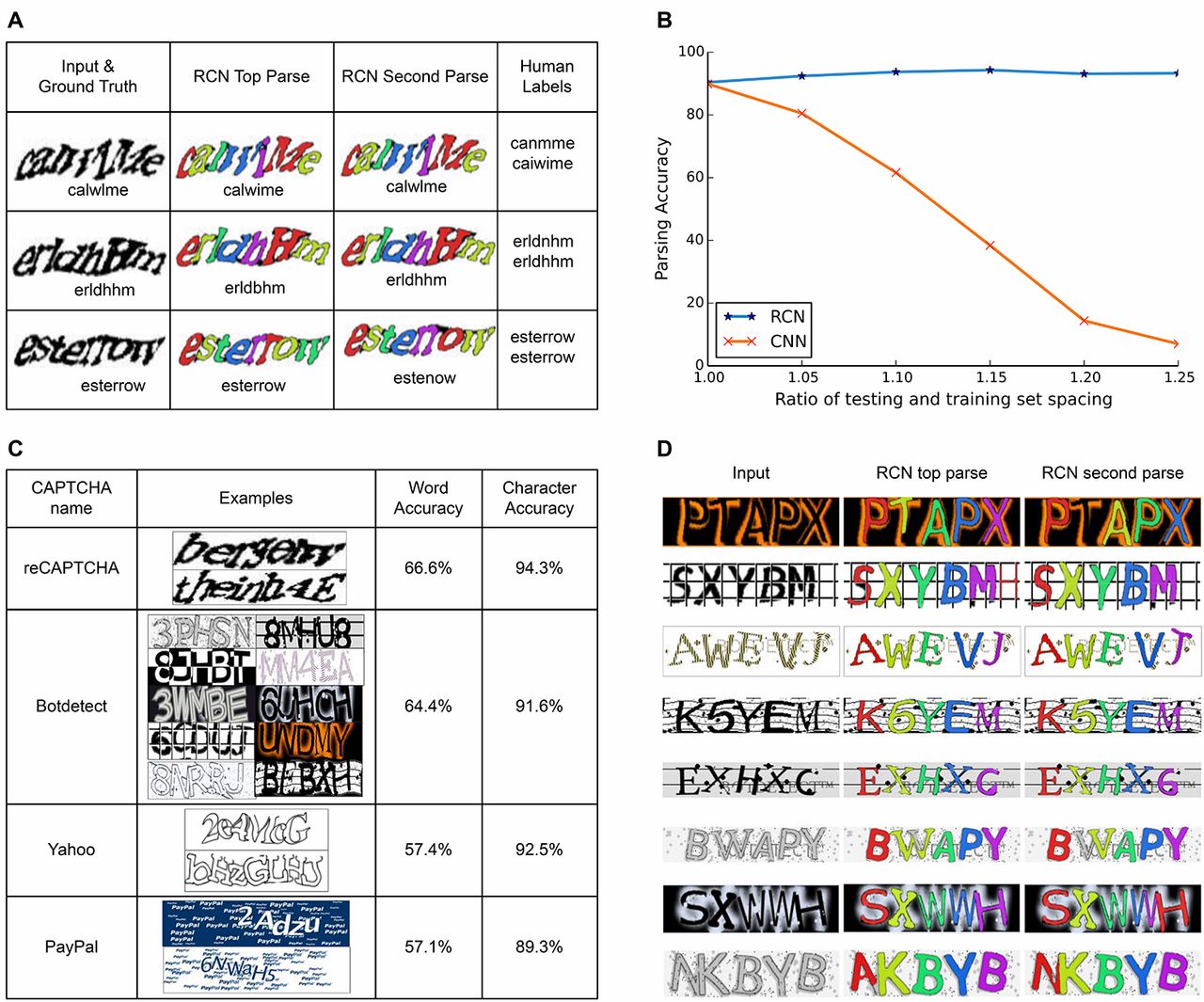
(A) Representative reCAPTCHA parses showing top two solutions, their segmentations, and labels by two different Amazon Mechanical Turk workers. (B) Word accuracy rates of RCN and CNN on the control CAPTCHA data set. CNN is brittle and RCN is robust when character-spacing is changed. (C) Accuracies for different CAPTCHA styles. (D) Representative BotDetect parses and segmentations (indicated by the different colors).
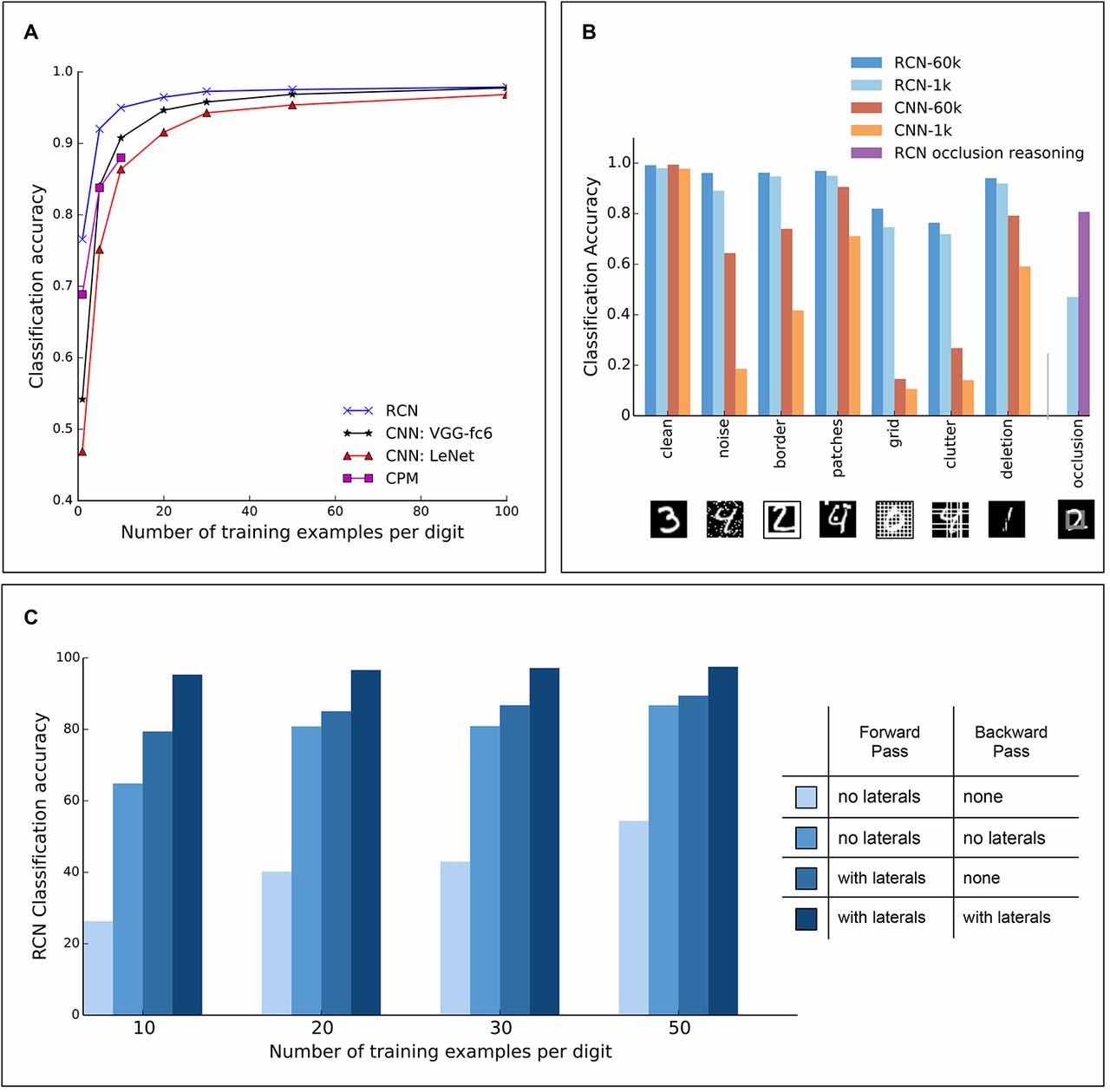
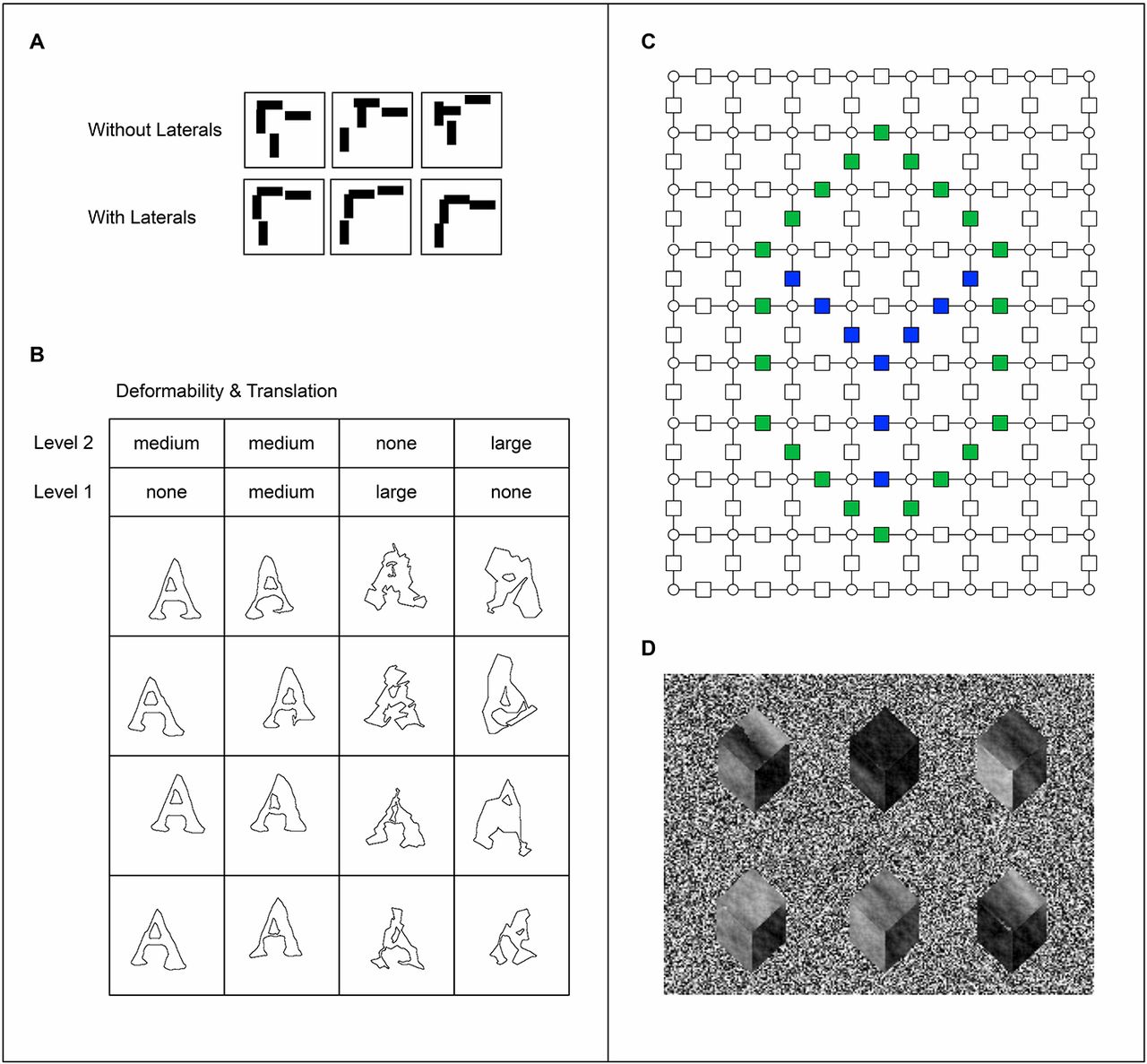
(A) MNIST classification accuracy for RCN, CNN, and CPM. (B) Classification accuracy on corrupted MNIST tests. Legends show the total number of training examples. (C) MNIST classification accuracy for different RCN configurations.

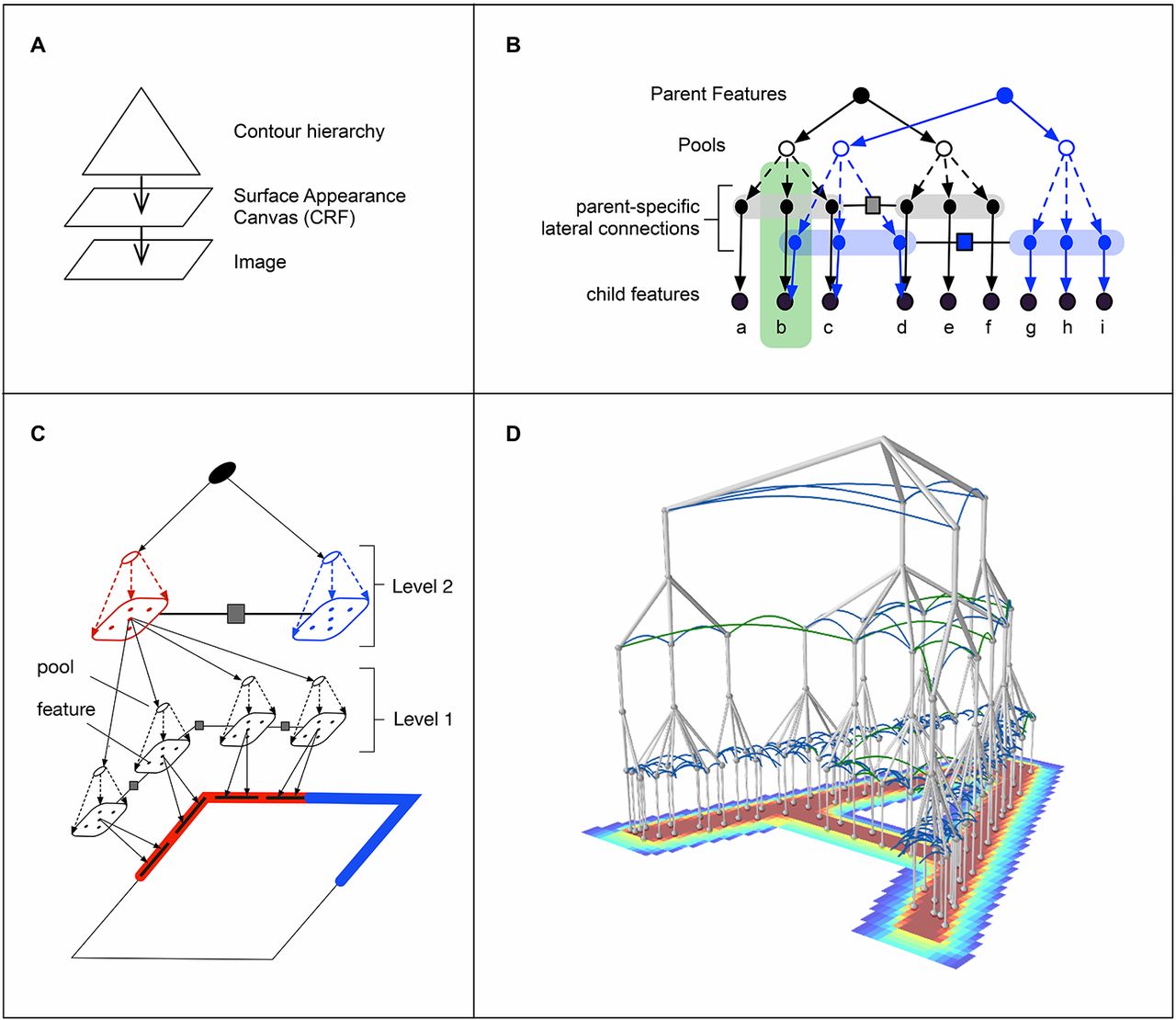
Generation, occlusion reasoning, and scene-text parsing with RCN. Examples of reconstructions (A) and reconstruction error (B) from RCN, VAE and DRAW on corrupted MNIST. Legends show the number of training examples. (C) Occlusion reasoning. The third column shows edges remaining after RCN explains away the edges of the first detected object. Ground-truth masks reflect the occlusion relationships between the square and the digit. The portions of the digit that are in front of the square are indicated by brown color and the portions that are behind the square are indicated by orange color. The last column shows the predicted occlusion mask. (D) One-shot generation from Omniglot. In each column, row 1 shows the training example and the remaining rows show generated samples. (E) Examples of ICDAR images successfully parsed by RCN. The yellow outlines show segmentations.

Application of RCN to parsing scenes with objects. Shown are the detections and instance segmentations obtained when RCN was applied to a scene parsing task with multiple real-world objects in cluttered scenes on random backgrounds. Our experiments suggest that RCN could be generalized beyond text parsing [see section 8.12 of (33) and Discussion].
O artigo foi publicado na edição de ontem da revista SCIENCE e pode ser lido e/ou baixado nos links abaixo:
Leiam o artigo na íntegra em: http://science.sciencemag.org/content/early/2017/10/26/science.aag2612/tab-pdf
Baixe o texto da pesquisa no formato PDF em: http://science.sciencemag.org/content/sci/early/2017/10/26/science.aag2612.full.pdf
NOTA EXPLICATIVA:
Não sabe o que é CAPTCHA?
CAPTCHA é um acrônimo da expressão “Completely Automated Public Turing test to tell Computers and Humans Apart” (teste de Turing público completamente automatizado para diferenciação entre computadores e humanos): um teste de desafio cognitivo, utilizado como ferramenta anti-spam, desenvolvido de forma pioneira na universidade de Carnegie-Mellon. Como o teste é administrado por um computador, em contraste ao teste de Turing padrão que é administrado por um ser humano, este teste é na realidade corretamente descrito como um teste de Turing reverso.
Um tipo comum de CAPTCHA requer que o usuário identifique as letras de uma imagem distorcida, às vezes com a adição de uma sequência obscurecida das letras ou dos dígitos que apareça na tela






{kind=link}